安装管理后台
- 快速开始
- 高级配置
- 后台运维
- 其他说明
- FAQ
- 1. 常见启动失败原因
- 2. 管理后台打开后空白、按钮点不动等问题
- 3. ElasticSearch "Result window is too large" 错误
- 4. 我的主机名显示为 "im-not-resolvable"
- 5. 管理后台打不开,Chrome 浏览器提示 ERR_CONNECTION_REFUSED
- 6. 无法发送邮件报警,提示 5XX 错误
- 7. ElasticSearch X-Pack 使用说明
- 8. 自己编译的后台,访问前端服务器 8086 端口提示 404 错误
- 9. 误删ES索引,如何处理?
- 10. 报警上传成功,后台看不到报警而且 ES 健康状态为 yello
- 11. 我使用 nginx 作为管理后台的反向代理,iast 扫描器无法连接,总是提示400错误
- 12. 管理后台假死,日志里出现大量 too many open files
- 13. 离线主机排查
- 14. rasp-cloud 启动卡住
快速开始
在开始之前,请先根据 软件下载 里的说明,下载 rasp-cloud.tar.gz,并解压缩到本地。
安装数据库
目前,我们使用了 ElasticSearch 和 MongoDB 两种数据库。前者用来存储报警和统计信息,后者用来存储应用、账号密码等信息。
目前我们对数据库的要求是,
- MongoDB 版本大于等于 3.6
- ElasticSearch 版本大于等于 5.6,小于 7.0 (ES 7.X 变化较大,暂无计划支持)
具体如何安装数据库,这里不在赘述。
启动管理后台
首先,编辑 conf/app.conf 文件,修正 ElasticSearch 和 MongoDB 两个服务器的地址。如果这两个数据库都安装在了本机,且使用默认端口,请跳过此步骤:
[prod]
EsAddr = http://127.0.0.1:9200
EsUser =
EsPwd =
MongoDBAddr = 127.0.0.1:27017
MongoDBUser =
MongoDBPwd =
关于 MongoDB 认证配置,可参考 mongoDB Linux 认证配置、重置密码、远程登录配置详解 文章操作;如果 MongoDB 有主从,只需要填写主地址。
然后,在终端里执行如下命令,启动后台服务器:
./rasp-cloud -d
最后,在浏览器里打开 http://your-ip:8086,登录管理后台。其中用户名固定为 openrasp,初始密码为 admin@123。如果不能访问,请检查防火墙设置,或者检查 logs/api/agent-cloud.log 下面的错误信息。
登录成功后,请根据 管理后台 - 添加主机 文档,了解如何添加第一台主机。
高级配置
后台负载均衡
在实际场景中,我们需要部署多个服务器,才能处理来自数十万主机的连接。因此,我们将管理后台拆分为 Agent 接口服务器 (AgentServer) 和 前端服务器 (PanelServer)。前者用于跟agent通信,比如心跳、日志上传,可以部署多个;后者用于展示数据、定时报警、修改配置,用户可访问这个后台来查看报警。后者用于发送报警邮件,部署多个会有重复报警的问题,所以目前只能部署一个。
在百度,我们会启动一个前端服务器,
./rasp-cloud -type=panel -d
然后在不同的机房,分别启动一个 agent 服务器(使用同一份 conf/app.conf 配置文件即可)
./rasp-cloud -type=agent -d
服务器部署完成后,请根据 管理后台 - 设置后台信息 文档,将所有的Agent服务器填入。之后就可以在 添加主机 界面上,生成自动安装命令了。
容量说明: 目前,在2核4GB的主机上,按照3分钟一个心跳计算,大概单台机器可容纳 1000个 客户端。
ElasticSearch 负载均衡
在使用ES集群时,EsAddr 填写一个服务器的地址即可。我们自动会调用 /_nodes/ 接口获取全部服务器信息并轮询,以避免单点问题。
配置项详细说明
以下配置均为在 conf/app.conf 中配置
Beego 相关
常用 beego 配置项如下,更多设置请参考 beego 官网 文档,
| 参数 | 说明 | 默认值 |
|---|---|---|
| appname | 应用名称 | 无 |
| httpaddr | http 监听IP | 0.0.0.0 |
| httpport | http 监听端口 | 8086 |
| runmode | 运行模式,dev 为开发模式,prod 为线上模式 | prod |
OpenRASP 相关
OpenRASP 可用配置项目如下,
| 参数 | 说明 | 默认值 |
|---|---|---|
| EsAddr | Elasticsearch 服务器地址,多个地址用逗号隔开 | http://127.0.0.1:9200 |
| EsUser | Elasticsearch 用户名 (X-Pack) | 空 |
| EsPwd | Elasticsearch 密码 (X-Pack) | 空 |
| EsTTL | Elasticsearch 数据过期时间,单位/天 | 365 |
| MongoDBAddr | MongoDB 连接地址,多个地址用逗号隔开 | 127.0.0.1:27017 |
| MongoDBName | 使用的 MongoDB 的数据库名称 | openrasp |
| MongoPoolLimit | MongoDB 连接池最大限制 | 2048 |
| MongoDBUser | MongoDB 认证用户名,该用户需要有操作 openrasp 数据库的权限,有认证才需要配置 | 空 |
| MongoDBPwd | MongoDB 认证密码 | 空 |
| LogMaxSize | 单个日志文件最大大小,超过就rotate当天日志 | 104857600 |
| LogMaxDays | 最多保留多少天的日志 | 7 |
| MaxPlugins | 每个App最多保留多少插件,超过删除最老的 | 30 |
| CookieLifeTime | 登录 cookie 有效期,单位/小时 | 168 |
| AlarmLogMode | 报警日志采集模式,file 模式将日志落地到文件,可配合 logstash 上传到 es;es 模式将日志直接写入到 ES | es |
| AlarmBufferSize | es 模式下日志缓冲区大小,当日志量过大,缓冲区满的情况下,将会出现日志丢失 | 300 |
| AlarmCheckInterval | 报警检查间隔时间,单位秒 v1.3 开始改为前端配置 |
120 |
| RequestBodyEnable | access.log中是否包含请求体信息 | false |
| DebugModeEnable | 是否开启Debug开关,打印调试信息 | false |
| ErrorLogEnable | 是否将错误日志记录到es | false |
| LogMaxSize | rasp每个日志文件大小(单位:字节) | 104857600 |
| LogMaxDays | rasp日志最长保留天数 | 10 |
| LogPath | rasp日志文件根路径 | /home/openrasp/logs |
| OfflineInterval | rasp主机离线时间判定超时阈值,允许范围为30~31622400(单位:秒) | 180 |
| RegisterCallbackUrl | rasp主机注册回调地址,如果失败将不会注册 | 空 |
开启 HTTPS
在 conf/app.conf 中加入以下配置即可,修改后重启后台生效:
EnableHTTPS = true
EnableHttpTLS = true
HttpsPort = 443
HTTPSCertFile = "cert.pem"
HTTPSKeyFile = "cert.key"
后台运维
升级后台
请登录到每一台部署了 rasp-cloud 的主机,并按照如下步骤进行升级:
如果是 v1.3.0 之前的后台
- 备份原来的配置文件,
conf/app.conf - 下载新的安装包,解压缩到相同目录
- 检查是否需要更新配置文件
- 执行命令
ps aux | grep rasp-cloud找到后台进程 PID - 对上述进程发出 HUP 信号,e.g
kill -HUP $PID - 检查后台是否可以正常访问
如果是 v1.3.0 甚至更高版本的后台
- 备份原来的配置文件,
conf/app.conf - 下载新的安装包,解压缩到相同目录
- 检查是否需要更新配置文件
- 执行 /path/to/rasp-cloud -s restart
- 检查后台是否可以正常访问
找回密码
请登录到后台所在的主机,执行如下命令,根据提示重置密码。目前密码强度要求是 8-50 位,必须包含数字和字母。
./rasp-cloud -type=reset
检查后台状态
请登录到后台所在的主机,执行如下命令即可:
%> ./rasp-cloud -s status
/rasp-cloud/
2020/02/11 18:13:39 The rasp-cloud is running!
查看后台版本
请登录到后台所在的主机,执行如下命令即可:
%> ./rasp-cloud -version
/rasp-cloud/
Version: 1.3
Build Time: 2020-02-11 17:56:52
Git Commit ID: d6902d60f8874e7255562544041edbd340e6b676
定期备份
在百度,我们以小时级别对 MongoDB 和 ElasticSearch 数据库进行备份。其中,MongoDB 需要备份 openrasp 数据库,可以使用 mongodump + mongorestore 实现;ElasticSearch 需要备份如下索引,可以用 snapshot 方式备份:
real-openrasp-report-data-{appid}
real-openrasp-attack-alarm-{appid}
real-openrasp-policy-alarm-{appid}
real-openrasp-error-alarm-{appid}
real-openrasp-dependency-data-{appid}
当然,如果公司有DBA团队,可以考虑托管给他们。
其他说明
Logstash 配置
当 AlarmLogMode 设置为 file 时,可使用 Logstash 采集文件日志。Logstash 样例配置如下,使用前请先修正日志路径
input{
file{
path=>[
## 1. 修改该处,将 $cloud-agent-home 替换为部署的 agent 模式后台的根目录
"$cloud-agent-home/openrasp-logs/attack-alarm/attack.log"
]
start_position => "beginning"
type => "attack-alarm"
codec => "json"
}
file{
path=>[
## 2. 修改该处,将 $cloud-agent-home 替换为部署的 agent 模式后台的根目录
"$cloud-agent-home/openrasp-logs/policy-alarm/policy.log"
]
start_position => "beginning"
type => "policy-alarm"
codec => "json"
}
}
output {
if [type] == "attack-alarm" {
elasticsearch {
## 3. 修改 ES 地址
hosts => "0.0.0.0:9200"
index => 'real-openrasp-%{type}-%{[app_id]}'
timeout => 30
document_type => '%{type}'
}
}
if [type] == "policy-alarm"{
elasticsearch {
## 4. 修改 ES 地址
hosts => "0.0.0.0:8200"
index => 'real-openrasp-%{type}-%{[app_id]}'
timeout => 30
document_type => '%{type}'
action => 'update'
document_id => '%{[upsert_id]}'
doc_as_upsert => true
}
}
}
FAQ
1. 常见启动失败原因
日志会打印到 logs/api/agent-cloud.log 里。如果启动时没有增加 -d 参数,我们将同时在前台打印错误消息,e.g
2018/12/14 09:55:11.393 [I] [environment.go:62] ===== start type: default =====
2018/12/14 09:55:11.408 [E] [mongo.go:54] [30002] init mongodb failed: no reachable servers
目前定义的错误如下,
| 错误码 | 说明 |
|---|---|
| 30001 | 日志初始化失败,如文件权限问题 |
| 30002 | MongoDB 初始化失败,如 MongoDB 地址无法连接、MongoDB 认证失败等等 |
| 30003 | ES 初始化失败,如 ES 地址无法连接 |
| 30004 | 配置错误 ,如未配置 Domain |
| 30005 | 启动模式错误,启动使用了 agent, panel 之外的,不支持模式 |
| 30006 | 管理员密码初始化失败 |
| 30007 | geoip 初始化失败,如 geoip 数据库文件权限问题 |
| 30008 | 后台管理员用户名密码重置失败 |
| 30009 | 创建默认 app 失败 |
| 30010 | -d 参数启动后台失败 |
具体错误信息请查看 nohup 控制台输出
2. 管理后台打开后空白、按钮点不动等问题
我们目前只兼容 Google Chrome 浏览器。如果页面出现任何问题,请按下 F12 调出开发工具,并检查控制台是否有错误输出。如下图中的红色字样:
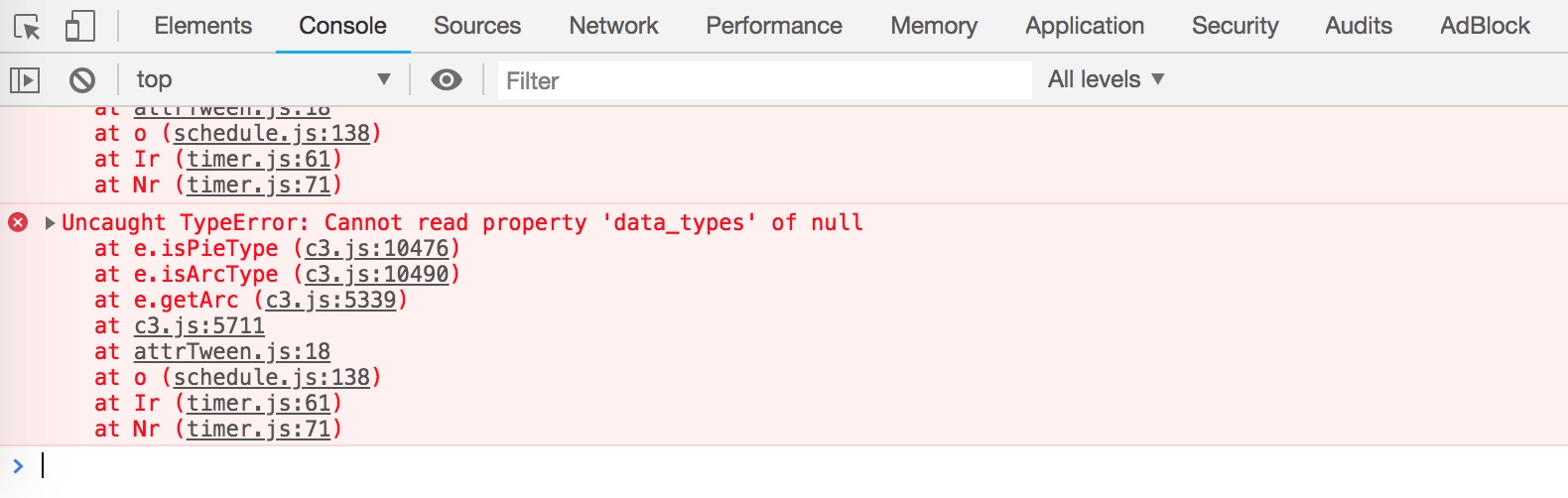
如果发现这种问题,请加入QQ群联系我们处理。
3. ElasticSearch "Result window is too large" 错误
如果你搜索的时间范围太大,ES 可能会爆出如下错误:
Result window is too large, from + size must be less than or equal to: [10000] but was [281280]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting.
这是因为你搜索的时间范围很大,导致ES需要对大量的数据进行排序。解决方法是打开 config/elasticsearch.yml,修改或者增加 index.max_result_window 配置,将它调整为一个较大的值。当然,修改这个值会消耗更多的内存。
4. 我的主机名显示为 "im-not-resolvable"
在 Java 版本里,我们使用了 InetAddress 来获取主机名称,如果这个主机名在 /etc/hosts 下面没有对应的记录,Java 将抛出 Unknown host 异常。在这种情况下,我们会将主机名设置为 im-not-resolvable,并让程序继续运行。
解决方法是,在 /etc/hosts 下面为你的主机名添加一条记录:
127.0.0.1 myhostname
添加后,重启 Java 服务器生效。再次启动时,我们会注册一个新的agent到后台。
5. 管理后台打不开,Chrome 浏览器提示 ERR_CONNECTION_REFUSED
默认情况下,后台监听地址为 0.0.0.0:8086。如果你无法访问服务器,请检查防火墙是否开启对应端口。对于基于 netfilter 的防火墙,你可以执行如下命令开放 8086 端口:
iptables -I INPUT -p tcp --dport 8086 -j ACCEPT
6. 无法发送邮件报警,提示 5XX 错误
大部分国内邮箱都不支持密码登录,需要申请授权码进行登录。如果你在使用下列邮箱,请参考他们的 FAQ 文档进行配置:
- 网易邮箱: 126/163/yeah.net
- QQ 邮箱: qq.com/vip.qq.com
- Coremail - 请联系销售
7. ElasticSearch X-Pack 使用说明
目前,后台使用的索引名称前缀为:
- real-openrasp-X (alias)
- openrasp-X
如果你在使用 X-Pack,且需要按照索引名称前缀进行授权,可以根据上述规则添加认证。若要查看当前 ES 的索引和别名列表,可访问如下URL:
http://elasticsearch_hostname:port/_cat/indices?v
http://elasticsearch_hostname:port/_cat/alias?v
8. 自己编译的后台,访问前端服务器 8086 端口提示 404 错误
前端文件在 dist 目录下,如果前端服务器返回 404 则说明这个目录不存在,或者 dist/index.html 不存在。
9. 误删ES索引,如何处理?
ES索引里只保存报警信息,误删索引不会导致agent信息丢失。若要完全重置ES,请先删除所有以 real-openrasp-、openrasp- 开头的索引,并重新启动 rasp-cloud 即可。rasp-cloud 会在启动时检查并重新创建索引。
10. 报警上传成功,后台看不到报警而且 ES 健康状态为 yello
为了避免阻塞,管理后台是异步将报警日志写入 ElasticSearch,因此 API 接口成功不代表报警保存成功。当 ES 服务器磁盘空间占用超过 95%,ES 会拒绝接受日志并抛出 cluster_block_exception 异常:
blocked by: [FORBIDDEN/12/index read-only / allow delete (api)]
修复方式请参考 Elasticsearch磁盘占用大于95%时将所有索引置为只读 文章解决。
11. 我使用 nginx 作为管理后台的反向代理,iast 扫描器无法连接,总是提示400错误
iast 扫描器使用 websocket upgrade 协议连接管理后台,nginx 需要同时传递 Upgrade 头才能工作:
server {
listen 84;
location / {
proxy_set_header Host $http_host;
proxy_pass http://172.17.0.4;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
否则会在管理后台 api/agent-cloud.log 看到如下错误
2020/02/07 11:37:47.784 [E] [iast.go:147] upgrade err: websocket: the client is not using the websocket protocol: 'upgrade' token not found in 'Connection' header
12. 管理后台假死,日志里出现大量 too many open files
参考 linux 打开文件数 too many open files 解决方法 修正 limits.conf 里的配置即可,修正后需要重新登录生效。
最后通过 ulimits -n 命令确认即可。
13. 离线主机排查
如果后台出现离线主机,请按照如下步骤排查:
- 检查客户端与后台是否连通。使用 curl 命令访问管理后台,检查是否能访问。
- 重启 Tomcat/PHP 服务器,检查主机是否上线。
- 检查客户端主机名、网卡信息是否有变化。如果有,后台信息会跟着变更,并产生一台新的主机。这个问题会在后续版本修正,即固定 rasp_id 到配置目录。
- 检查管理后台系统时间是否正确。
14. rasp-cloud 启动卡住
目前已知的情况有
- beego自身存在BUG,如果日志目录被链接到 /dev/null,将会卡住。e.g log/access 目录